Java | Technology
Definition of Done for User Stories vs. Bugs 
Martin van Vliet 19 Dec, 2008





In this article I want to provide you with a simple abstract in order for you to discover the container paradigm yourself. We’ll try to answer questions like: what are containers, how are they made and why are they great?
The first time I heard about ‘containers’ I thought that containers were very small sized stripped down nodes. Well, I can tell you that’s definitely not the case.
First things first, containers are not VMs. Containers provide a way to virtualize an operating-system so that multiple workloads run on top of a single operating-system (in a sense that the same kernel is shared among the containers). VMs virtualize the hardware so that every VM has it’s own isolated instance of an operating-system (by using a hypervisor). This might be hard to grasp when you start learning about containerization and seems vague, but I’ll try my best to clear things up along the way..
Containerization provides a clean separation of concerns. They offer an abstraction from the environment they are run on top of. We pack all of the dependencies and configuration together so we can easily move it around.
An analogy I like to refer to when describing containerization is that we have small apartments that share plumbing and central heating with other small apartments, but every appartment has its own furntiture, its own locked front door and some apartments may have a cat running around the place called Gizmo, whilst others don’t. We’ll put the apartment in a box including a template of how plumbing and central heating should be done incase a new energy company decides to take over, and we call it a ‘container’.
Due to this layer of system abstraction a container becomes very portable, whether you want to deploy the container to a staging environment or production, the content of the container remains the same (from application code to installed dependencies). If we wanted to move our apartment to another building we have everything ready. We now own metadata from if the cat is running around the place or not, to metadata of the available furntiture, to the template of how the plumbing and central heating should be done.
This allows for a far more lightweight portable experience. We have less to bootstrap and use just a fraction of the memory compared to providing a new isolated instance of an operating-system.
How are processes isolated whilst they use the same kernel? To answer this question we’ll need to dive into the Linux kernel. Are you already on the edge of your seat?
The Linux kernel has a few features such as:
Namespaces are one of the building blocks of isolation, they perform the isolation at a kernel level. Similar to how chroot works, which jails the process in a different root directory, namespaces separate other aspects of the system. It’s an integral part of the architecture of tools like Docker. Namespaces were added in the 2.6.24 Linux kernel release back in 2008 (it’s good to note that there are several types of namespaces added to the kernel, not all of them were added in this release).
The Mount or mnt. namespace.
The Mount namespace virtually partitions the file system so that processes running in a mount namespace cannot access file outside of their mount point.
The Process or pid. namespace.
In Linux processes follow a branch, a so called process tree, every PID in the tree refers to an active process. The process namespace cuts off a branch of the process tree, and doesn’t allow access further up the process branch. This is essential because if a process is priviliged to inspect or may even be able to kill other processes we would have a problem. The process that does this remains in the parent namespace, in the original process tree, but makes the child the root of its own process tree.
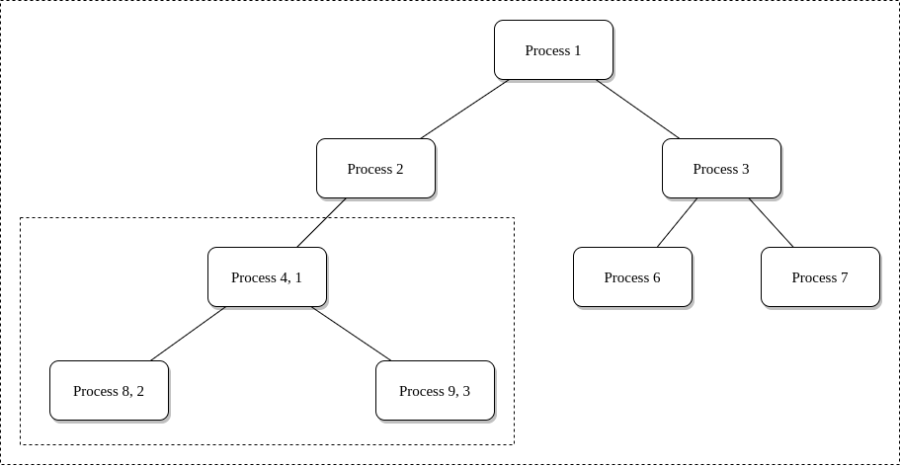
4 is the PID in the parent process tree and 1 is the PID in the new child process tree.
With PID namespace isolation, processes in the child namespace have no way of knowing of the parent processes its existence. However, processes in the parent namespace have a complete view of processes in the child namespace, as if they were any other process in the parent namespace. The PID namespace prevents the process from seeing or interacting with other processes.
The Network or net. namespace.
A network namespace allows processes to see a different set of networking interfaces and routing tables. In order to provide a usable network interface in the child network namespace we are required to create an additional virtual network interface.
To have incoming and outgoing traffic we must be able to communicate from the parent network namespace to the virtual interface in the child network namespace. This can be achieved by creating a bridge and a routing process. As this is quite a complex subject I recommend to read upon this yourself.
We now know the theory behind system isolation at the kernel level, but what if we also wanted to restrict certain resource usages of this isolated component? This is where control groups come in handy. Lets say that I want this specific apartment to not use more electricity than 0,8702 kWh when someone is home, this can be interpreted as not using more than N amount of memory for a group of isolated processes.
What if we wanted to prevent certain syscalls to be made from the container to the kernel? Apartment 121 should not have the rights to turn on the lights, could be the equivalent of telling a container that it has no rights to access the internet. Telling a container what its allowed to do and what not is defined in profiles. You can pass different profiles to different containers. The default profile for a Docker container can be viewed here in the Docker repository on Github, it blocks 44 syscalls out of the 300 available ones.
Seccomp uses the Berkeley Packet Filter program, this allows you to also setup custom filters. You can limit syscalls by providing conditions on how or when it should be limited when the syscall is made. The seccomp filters replace the syscalls with pointers to the Bpf program, which will perform the execution instead of the syscall.
Now that we have a basic understanding of the features, lets do some hands on by making a ‘container’ from scratch. It turns out that it’s pretty easy to make new namespaces, you can just run unshare. Time to make a new PID namespace and run Bash in it.
[ec2-user@]$ sudo unshare --fork --pid --net --mount-proc bash
Where are we? It seems like we are in the branched off process tree we spoke about earlier, I’m not able to see any other processes running in this process tree besides Bash, that’s good, we like isolation!
[root@ec2-user]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.1 0.4 124860 4028 pts/0 S 16:35 0:00 bash
root 16 0.0 0.3 164364 3924 pts/0 R+ 16:35 0:00 ps aux
I also added a ‘–net’ argument to the ‘unshare’ command we ran earlier, this creates an independent IPv4 and IPv6 stack. By default new network namespaces will have a loopback device but no other network devices. To be able to access the internet from your network namespace I recommend reading upon network namespace configurations.
[root@ec2-user]# ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Time to fiddle around with the control group we spoke about earlier. I gave an example of restricting a group of processes their memory usage, before being able to do this, we need to make a new level in the cgroup hierarchy. I named it ‘mymemgroup’.
[ec2-user@]$ sudo cgcreate -a ec2-user -g memory:mymemgroup
Lets see what’s inside of the ‘mymemgroup’ memory cgroup..
It looks like a bunch of files containing configurations for the memory cgroup.
[ec2-user@]$ ls -l /sys/fs/cgroup/memory/mymemgroup
total 0
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 cgroup.clone_children
--w--w---- 1 ec2-user root 0 3 jul 17:13 cgroup.event_control
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 cgroup.procs
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.failcnt
--w--w---- 1 ec2-user root 0 3 jul 17:13 memory.force_empty
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.failcnt
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.slabinfo
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.failcnt
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.kmem.usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.max_usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.failcnt
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.limit_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.memsw.usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.move_charge_at_immigrate
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.numa_stat
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.oom_control
---------- 1 ec2-user root 0 3 jul 17:13 memory.pressure_level
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.soft_limit_in_bytes
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.stat
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.swappiness
-r--r--r-- 1 ec2-user root 0 3 jul 17:13 memory.usage_in_bytes
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 memory.use_hierarchy
-rw-rw-r-- 1 ec2-user root 0 3 jul 17:13 notify_on_release
-rw-rw-r-- 1 root root 0 3 jul 17:13 tasks
So many possible ways of restricting our memory usage, lets try to see what the hard limit for our allocated kernel memory is by checking the value of memory.kmem.limit_in_bytes.
[ec2-user@]$ cat /sys/fs/cgroup/memory/mymemgroup/memory.kmem.limit_in_bytes
9223372036854771712
This looks like the highest positive signed 64-bit integer (263-1) rounded down to multiples of 4096 (212), but why? After some digging in the Linux Kernel I found that the value is set to the default PAGE_COUNTER_MAX and it’s multiplied by PAGE_SIZE when reading the value . It’s not the exact number of possible memory in bytes as it’s rounded down to where the last bytes drop off.
This number is the maximum for holding a number in binary in a memory store and apparently it’s the default value for the memorygroup its limit_in_bytes property.
Lets try to alter the value and lower it to 5 megabytes, I rather be on the safe side with our container.
[ec2-user@]$ sudo echo 5000000 > /sys/fs/cgroup/memory/mymemgroup/memory.limit_in_bytes
[ec2-user@]$ cat /sys/fs/cgroup/memory/mymemgroup/memory.limit_in_bytes
4997120
Time to use the cgroup, we can use cgexec to run a task in a given cgroup. Lets run Bash in our 5 megabyte restricted cgroup!
[ec2-user@]$ sudo cgexec -g memory:mymemgroup bash
We now want to test the behaviour of our cgroup and see how it responds to exceeding the allocated memory, 5 megabytes. I think that ‘yum get update’ uses a bit more to initiate this process.
‘Killed’! It looks like the OOM (“Out of Memory”) Killer terminated the process and did its job correctly, thanks OOM Killer.
The OOM Killer is daemon that is called by the Linux kernel if the system is critically low on memory or when a process is trying to bypass a memory limit. Actually, this daemon has many more features than the ones I just explained, I recommend to read upon it.
[root@ec2-user]# sudo yum get update
Killed
It seems like we did a good job! We created an isolated environment and limited our memory usage successfully.
That’s right. I was sitting at the edge of my seat when fiddling around with this, though I quickly had to remind myself that I’m no container expert and that I shouldn’t try to reinvent the wheel, ever. There’s a wide range of tools like Docker and lower level container clients that you can play around with to create containers. Playing around with these Linux kernel features is great to get a good grasp on containerization, but that’s it (for me). If you would like to dive more into this subject, I recommend reading the footnotes at the end of this article.
Containers are best used in a microservice architecture, as each service is independent and loosely-coupled to serve its own responsibility as a service proxy, we can easily assign one container to one microservice and measure by this rule. As containers are easy to spin up it becomes easy to scale-out. Microservices scale independent from each other and data can be decentralized as there is no need to maintain the same type of database behind every microservice. One microservice might use a document store such as Elasticsearch while another one uses a database such as Redis. I would recommend to read upon how containers and microservices go hand in hand very well as I’m just providing you with a simple abstract.
Now that you have microservices you’re required to implement lifecycle and task management such as: load balancing, scaling policies, routing, health monitoring and security policies. There’s some great tools out there such as Google Cloud Run, AWS Fargate and Kubernetes to orchestrate your container workload.
Lets take our local supermarket as an example. This supermarket is split up in 3 logical independent components (microservices).


